
Prosimo adds Cloud-Native Networking Suite
Prosimo, which offers an Application eXperience Infrastructure (AXI) platform for secure application delivery in multi-cloud environments, introduced a Cloud-Native Networking ...
Prosimo, which offers an Application eXperience Infrastructure (AXI) platform for secure application delivery in multi-cloud environments, introduced a Cloud-Native Networking ...

PsiQuantum named Roland Acra as Chief Business Officer responsible for the company’s business strategy, including commercial, global market expansion, quantum ...

OpenLight released its process design kit (PDK) for use with the Synopsys photonic IC design solution, and includes indium phosphide ...

Ayar Labs announced the hiring of Lakshmikant (LK) Bhupathi, Vice President of Products, Strategy and Ecosystem, and Scott Clark, Vice ...

https://youtu.be/3TsYgWaKGuUAstera Labs has demonstrated the industry's first CXL memory pooling solution to reduce memory stranding, optimize memory utilization and reduce ...

Marvell has confirmed that that leading cable manufacturers, including Amphenol, Molex, and TE Connectivity, are sampling to cloud data center ...
Intel's subsidiary, Mobileye, filed a registration statement on Form S-1 with the U.S. Securities and Exchange Commission for an initial ...

Tarana previewed an upcoming software update and an expansion into the the 6 GHz unlicensed band in the U.S. and ...

Avicena is demonstrating its LightBundle multi-Tbps chip-to-chip interconnect technology at this week's ECOC22 exhibition in Basel, Switzerland.The company says the ...
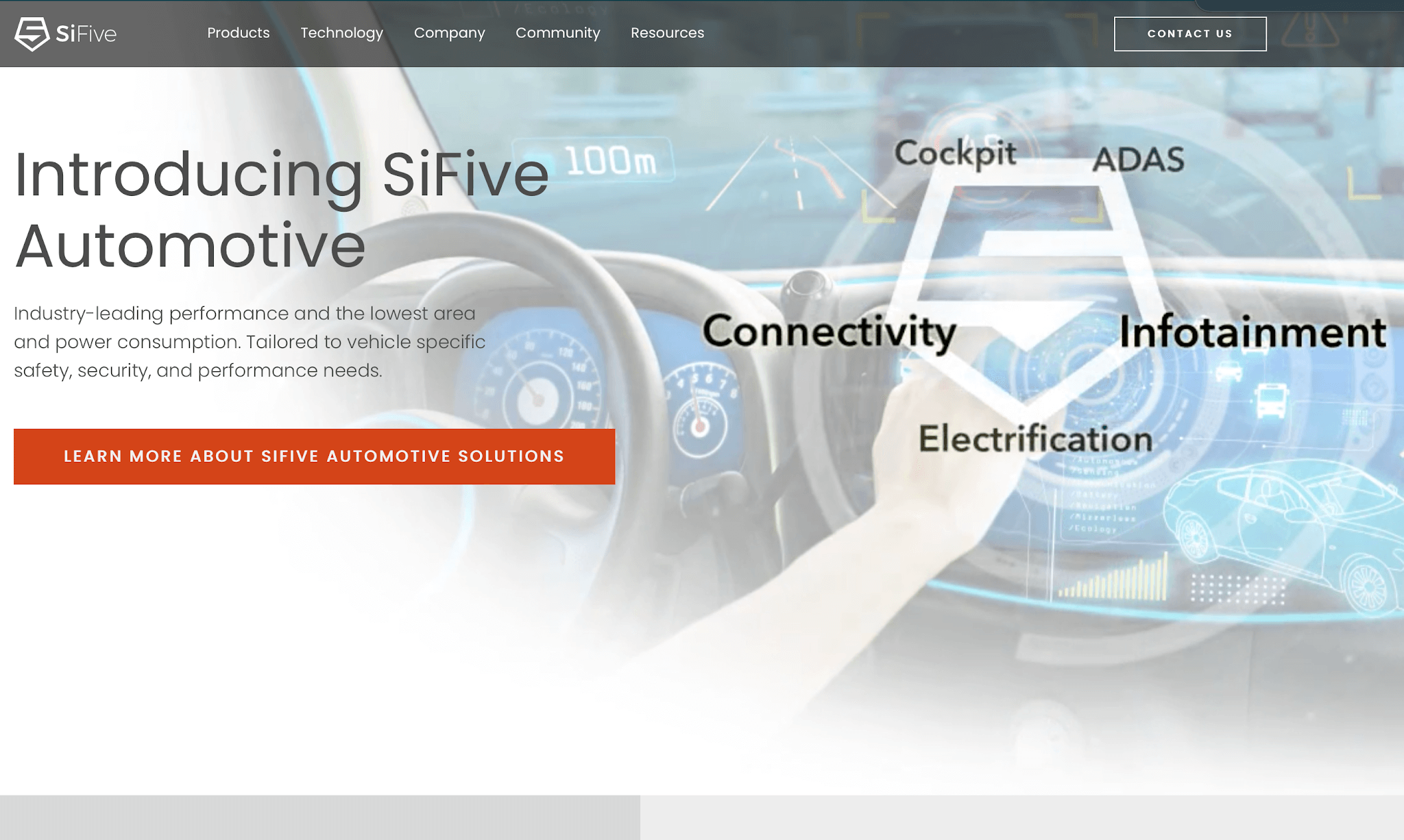
SiFive introduced three RISC-V processors for automotive manufacturers and their suppliers.The processors target current and future applications like infotainment, cockpit, ...

ZEDEDA, a start-up based in San Jose, California, focused on edge orchestration, announced the following changes to its executive team:Erik ...
Lightmatter, a start-up based in Boston developing a new class of photonic processing chip, named Richard Ho as its new ...

The CXL Consortium announced the release of the CXL 3.0 specification, doubling the data rate to 64GTs compared to the ...
A private dossier for networking and telecoms









