
Algar Telecom upgrades subsea infrastructure with Infinera
Algar Telecom, a leading provider of telecom and IT solutions in Brazil, has selected Infinera's GX Series Compact Modular Platform ...
Algar Telecom, a leading provider of telecom and IT solutions in Brazil, has selected Infinera's GX Series Compact Modular Platform ...

Sparkle and Trans Ocean Network, a Panamanian telecommunications company, will form a joint venture in Panama for the construction of ...
Google and Facebook unveiled plans for the Apricot subsea cable system, a 12,000-kilometer-long cable will connect Japan, Taiwan, Guam, the ...
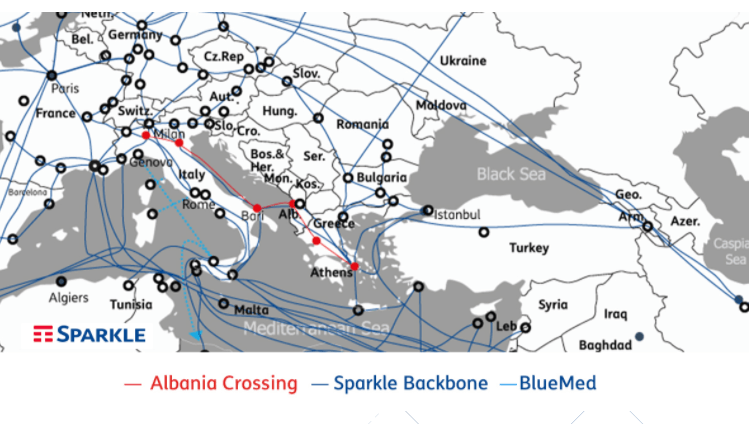
Sparkle activated Albania Crossing, a new direct route that is the shortest path from Athens to Milan.The new optical fiber ...

Sparkle announced the availability of Genome, its new integrated set of platforms and tools for Network Automation, Programmability and Virtualization ...
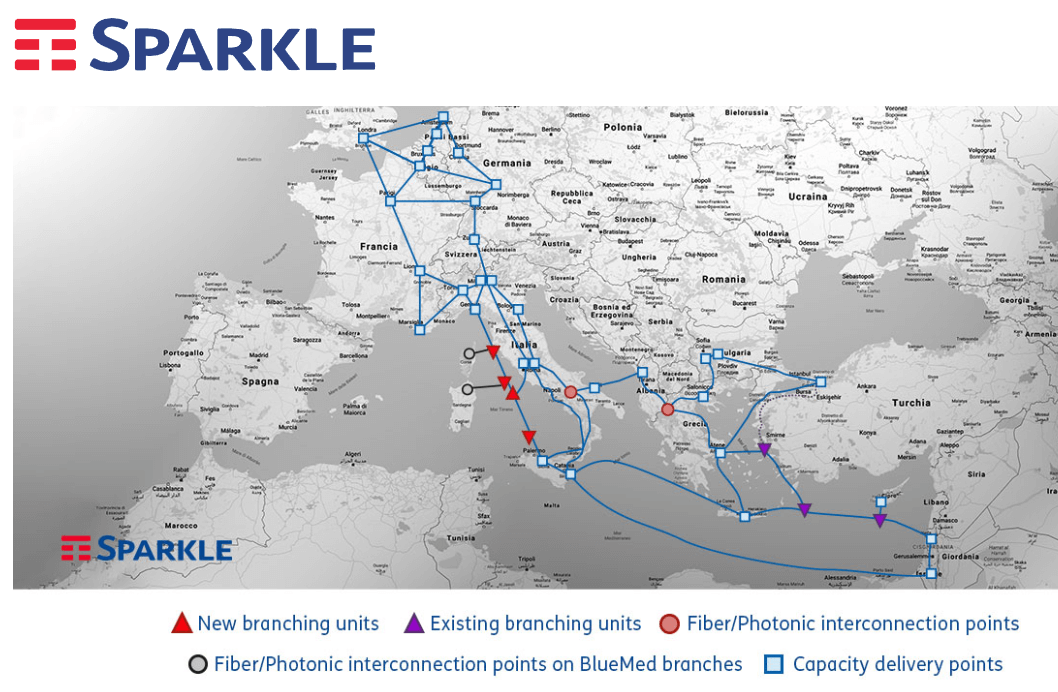
Sparkle, the first international service provider in Italy and among the top 10 global operators, announced plans for a new ...

ECI introduced its TM1200, a 1.2T blade (dual 600G channel) for its Apollo DWDM transport systems, enabling programmable, adaptive optical ...

IBM is launching a Spark-as-a-Service offering on Bluemix following a successful 13-week Beta program with more than 4,600 developers using ...
A private dossier for networking and telecoms









