
U.S. blocks shipments of NVIDIA’s A100 and H100 to China, Russia
The U.S. government has imposed an export restriction on NVIDIA's A100 and forthcoming H100 integrated circuits to China (including Hong ...
The U.S. government has imposed an export restriction on NVIDIA's A100 and forthcoming H100 integrated circuits to China (including Hong ...

Marvell has joined the Universal Chiplet Interconnect Express (UCIe) Consortium as part of its ongoing development of open chiplet interconnect ...

NVIDIA and SoftBank cancelled the acquisition of Arm Limited by NVIDIA. The companies cited significant regulatory challenges.SoftBank said it now ...

The U.S. Federal Trade Commission (FTC) sued to block the $40 billion proposed acquisition of Arm Ltd. by Nvidia Corp.The ...
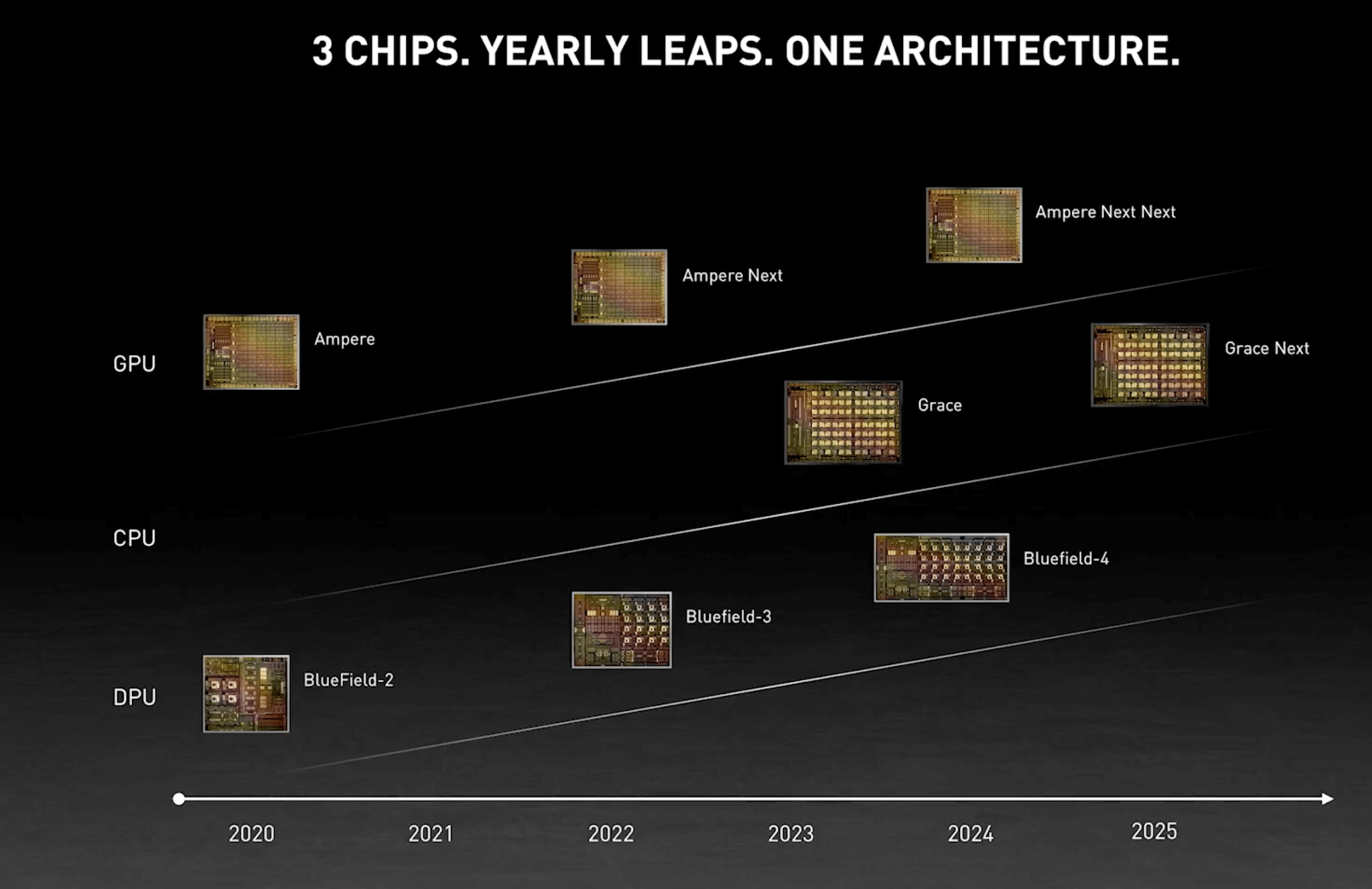
NVIDIA outlined a roadmap for the next two generations of its BlueField data processing unit (DPU) chips.The current generation, BlueField-2, ...

In a deal that will redefine the semiconductor market, NVIDIA agreed to acquire Arm Limited from Softbank for $40 billion. ...

NVIDIA has acquired Cumulus Networks. Financial terms were not disclosed. Cumulus, which was founded in 2010 by JR Rivers and ...

NVIDIA completed its $7 billion acquisition of Mellanox Technologies. The deal was originally announced on March 11, 2019. NVIDIA says ...
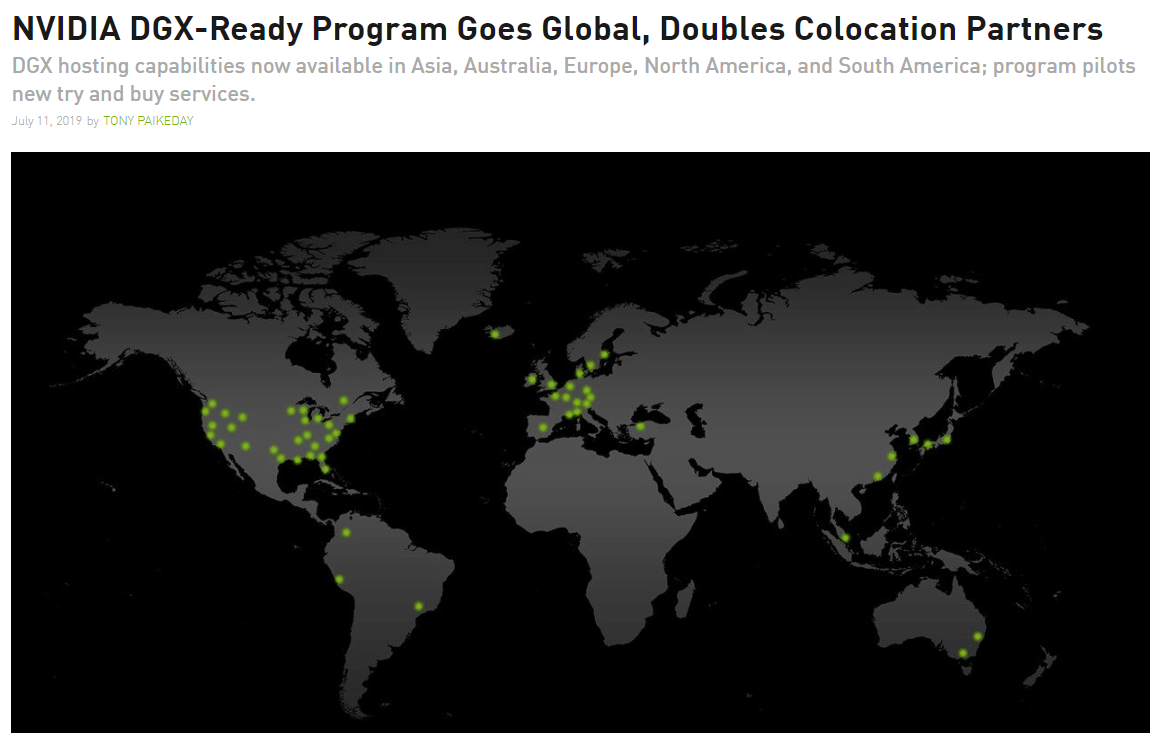
NVIDIA announced the international expansion of its DGX-Ready Data Center program with three new partners in Europe, five in Asia ...

Mellanox Capital, which is the investment arm of Mellanox Technologies, has made equity investments in storage start-ups CNEX Labs and ...

Mellanox Technologies introduced its data center Ethernet Cloud Fabric (ECF) technology based on its second generation, Spectrum-2 silicon, which can ...

Mellanox Technologies reported record revenue of $305.2 million in the first quarter, an increase of 21.6 percent, compared to $251.0 ...
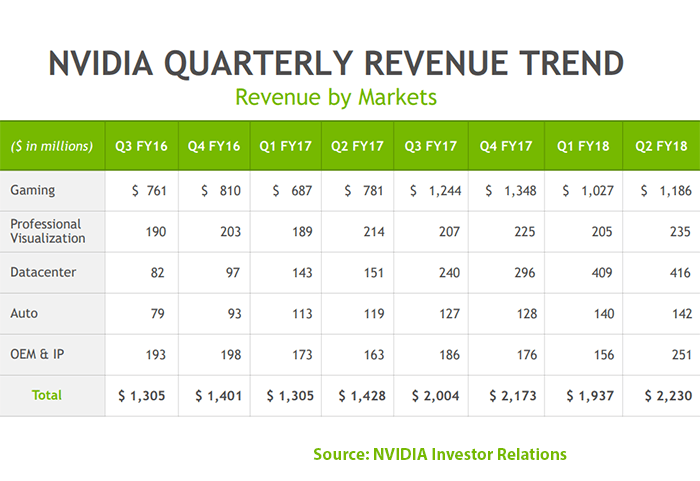
NVIDIA reported record revenue for its second quarter ended July 30, 2017, of $2.23 billion, up 56 percent from $1.43 ...
A private dossier for networking and telecoms










