
EXFO’s quarterly sales rise 7.8% to US$64.7 million
EXFO reported sales of US$64.7 million in the second quarter of fiscal 2018, up 7.8% year-over-year. Sales were up 5.2% ...
EXFO reported sales of US$64.7 million in the second quarter of fiscal 2018, up 7.8% year-over-year. Sales were up 5.2% ...
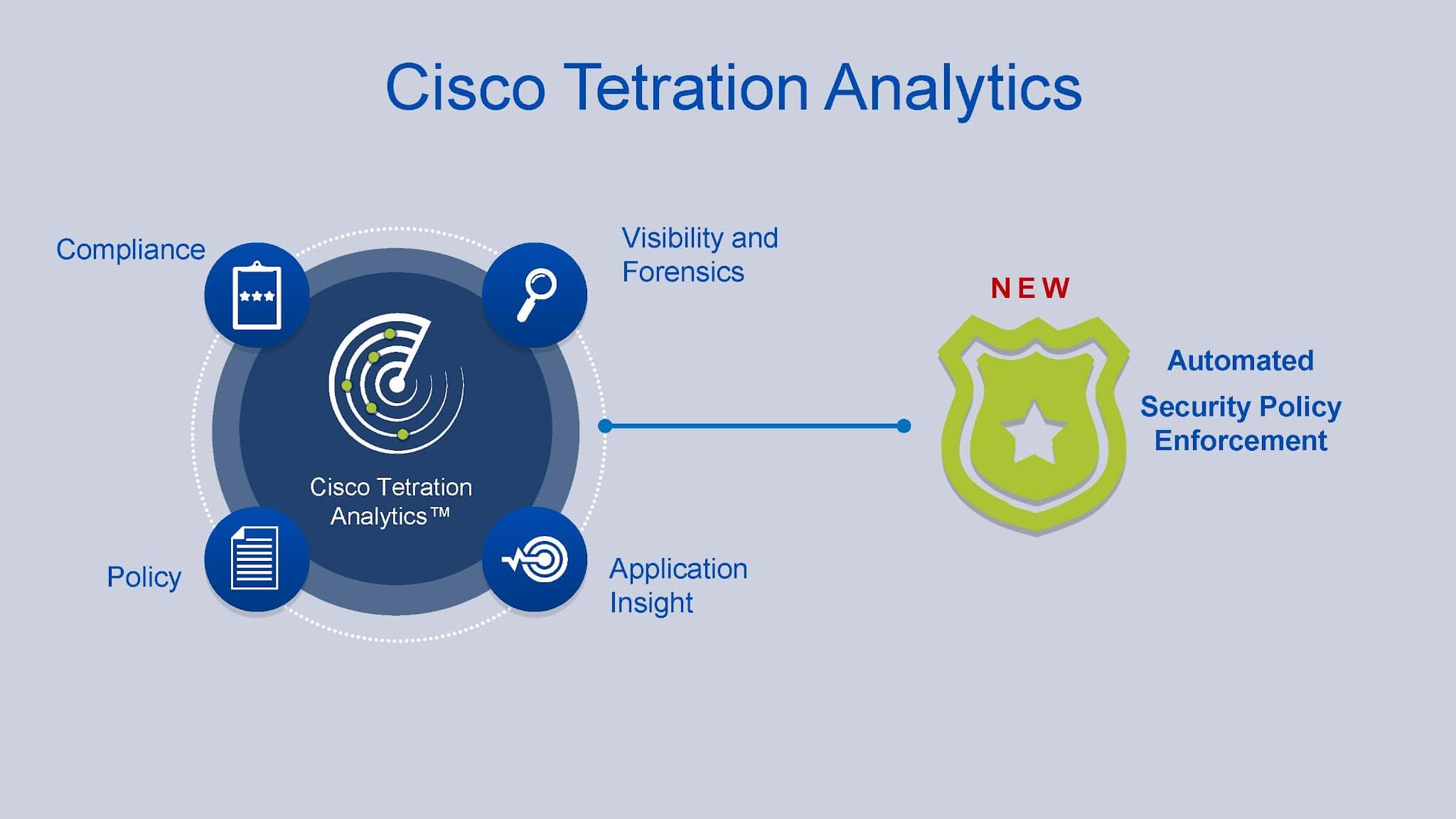
Cisco announced new capabilities for its Tetration Analytics framework including automated policy enforcement derived from its deep inspection of packet ...
Hewlett Packard Enterprise announced a new strategic partnership with Arista Networks to provide secure Hybrid IT solutions built on their ...

Fortinet agreed to acquire AccelOps, a start-up based in Santa Clara, California, that specializes in network security monitoring and analytics ...

Gigamon unveiled its Metadata Engine for their GigaSECURE Security Delivery Platform (SDP). The solution centrally generates and aggregates contextual information ...
A private dossier for networking and telecoms










