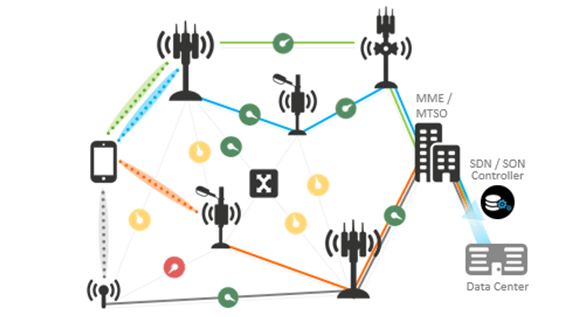
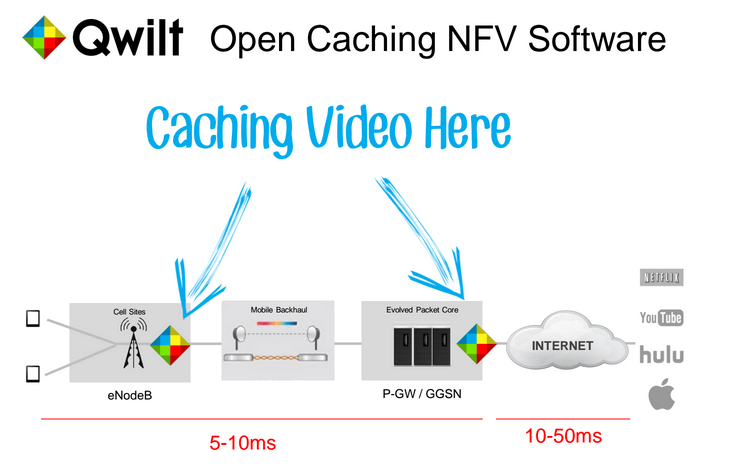
Juniper advances its vision for the new Cloud Metro
Juniper Networks outlined its vision, strategy and products for the Cloud Metro – a new category of solutions optimized for metro transformation, sustainable business growth, and powered by AI-enabled, cloud-delivered automation. Cloud Metro is defined as the “new edge”, where connectivity, edge cloud hosting, and service experience converge. Where as the traditional metro network was […]