AMD completes its $1.9 billion acquisition of Pensando
AMD completed its previously-acquisition of Pensando Systems in a transaction valued at approximately $1.9 billion. Pensando’s distributed services platform will expand ...
AMD completed its previously-acquisition of Pensando Systems in a transaction valued at approximately $1.9 billion. Pensando’s distributed services platform will expand ...
AMD agreed to acquire Pensando, a Silicon Valley start-up offering a software-defined edge services platform powered by a custom packet ...

AMD announced the general availability of its 3rd Gen AMD EPYC data center processors with AMD 3D V-Cache technology, formerly ...

AMD completed its previously-announced acquisition of Xilinx in an all-stock transaction. Xilinx stockholders received 1.7234 shares of AMD common stock ...
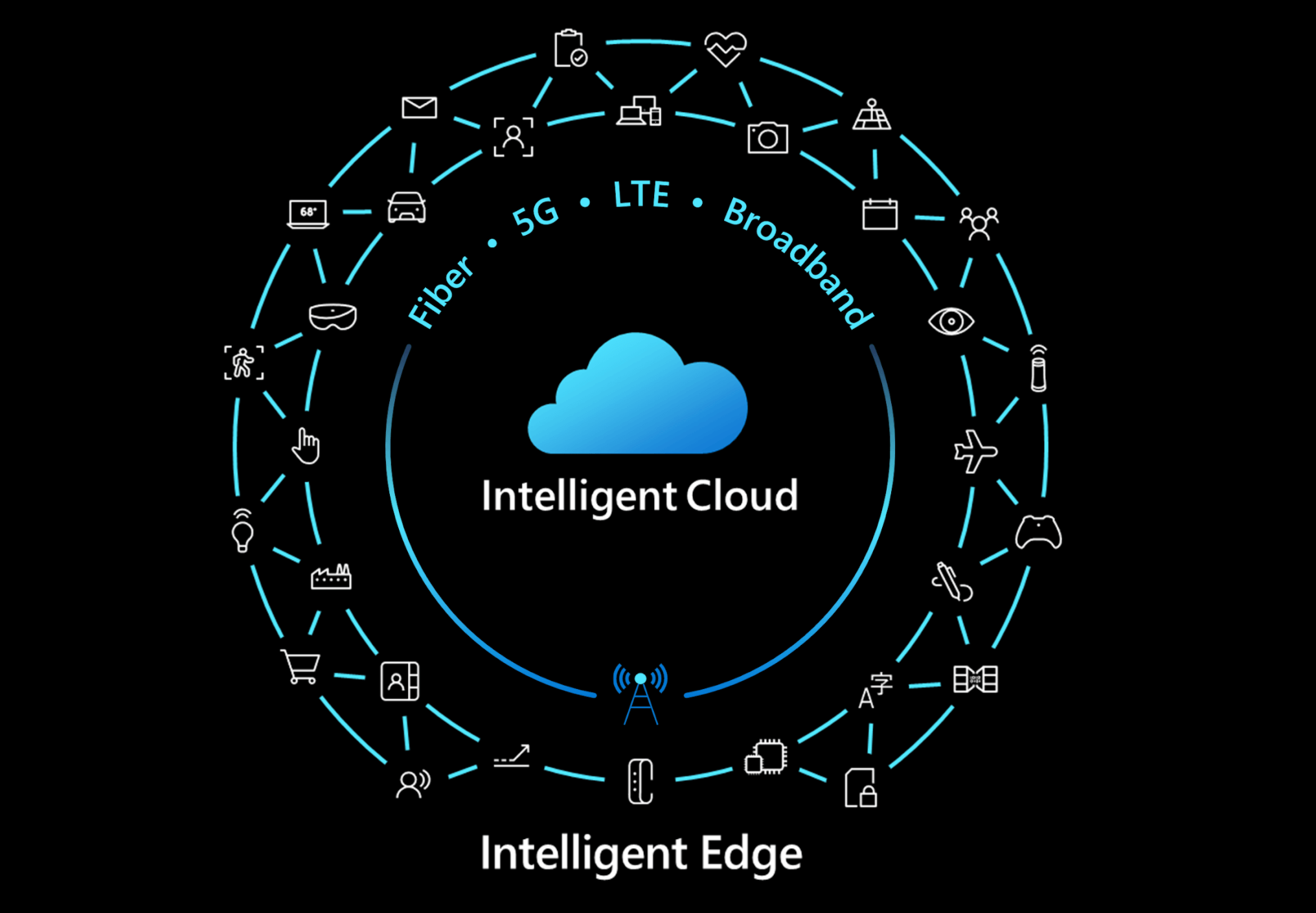
AT&T will power its mobile network on Microsoft's Azure for Operators cloud starting with the 5G and migrating existing and ...

DISH Network will construct its 5G Open Radio Access Network (O-RAN) network on AWS.DISH, which is partnering exclusively with vendors ...

AT&T has selected Amdocs'cloud-native Openet 5G solution to monetize services over its 5G network. The 5G monetization solution is certified ...

Amdocs and Microsoft are expanding their alliance to help communication service providers (CSPs) with differentiated, cloud-based services. Amdocs and Microsoft ...

Amdocs announced new customer wins with Comcast Business, Verizon and Amazon Web Services (AWS). Some highlights: Amdocs now supports Comcast ...

AT&T, which recently announced plans to contribute its Enhanced Control, Orchestration, Management and Policy (ECOMP) platform to open source, announced ...
A private dossier for networking and telecoms









