
Broadcom begins volume shipment of 51.2 T Tomahawk 5
Broadcom has begun volume shipments of its Tomahawk 5 family of Ethernet switch/router chips. Tomahawk 5 offers 51.2 Tbps of ...
Broadcom has begun volume shipments of its Tomahawk 5 family of Ethernet switch/router chips. Tomahawk 5 offers 51.2 Tbps of ...

OpenLight, a start-used based in Mountain View, California, released its first 800G DR8 photonic integrated circuit (PIC) design targeted at ...

PsiQuantum named Roland Acra as Chief Business Officer responsible for the company’s business strategy, including commercial, global market expansion, quantum ...

Marvell Technology has begun sampling a 5nm 1.6T Ethernet PHY with 100G I/O capability, featuring built-in Media Access Control security ...

OpenLight released its process design kit (PDK) for use with the Synopsys photonic IC design solution, and includes indium phosphide ...

Astera Labs, a start-up based in Santa Clara, California, raised $150 million in Series-D funding with a $3.15B valuation for ...

Ayar Labs announced the hiring of Lakshmikant (LK) Bhupathi, Vice President of Products, Strategy and Ecosystem, and Scott Clark, Vice ...

MaxLinear reported Q3 net revenue of $285.7 million, up 2% sequentially and up 24% year-over-year. GAAP gross margin was 58.6%, ...

https://youtu.be/3TsYgWaKGuUAstera Labs has demonstrated the industry's first CXL memory pooling solution to reduce memory stranding, optimize memory utilization and reduce ...

Marvell has confirmed that that leading cable manufacturers, including Amphenol, Molex, and TE Connectivity, are sampling to cloud data center ...
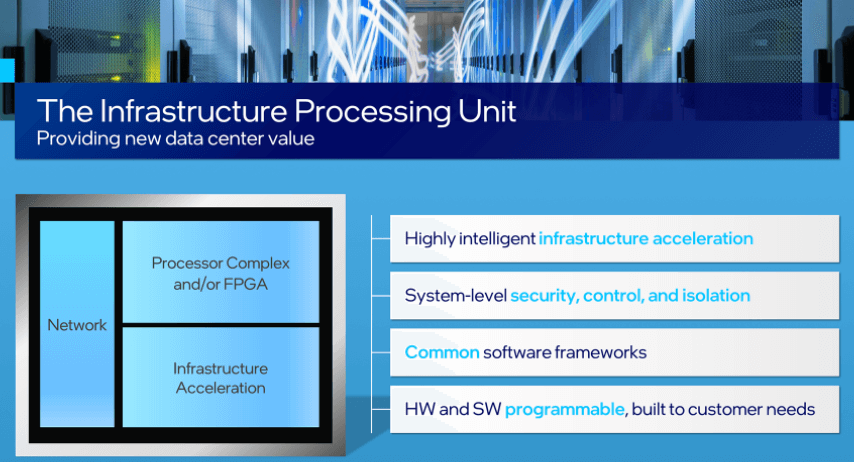
Google Cloud introduced its Compute Engine C3 VMs powered by the 4th Gen Intel Xeon Scalable processor and Google’s custom ...
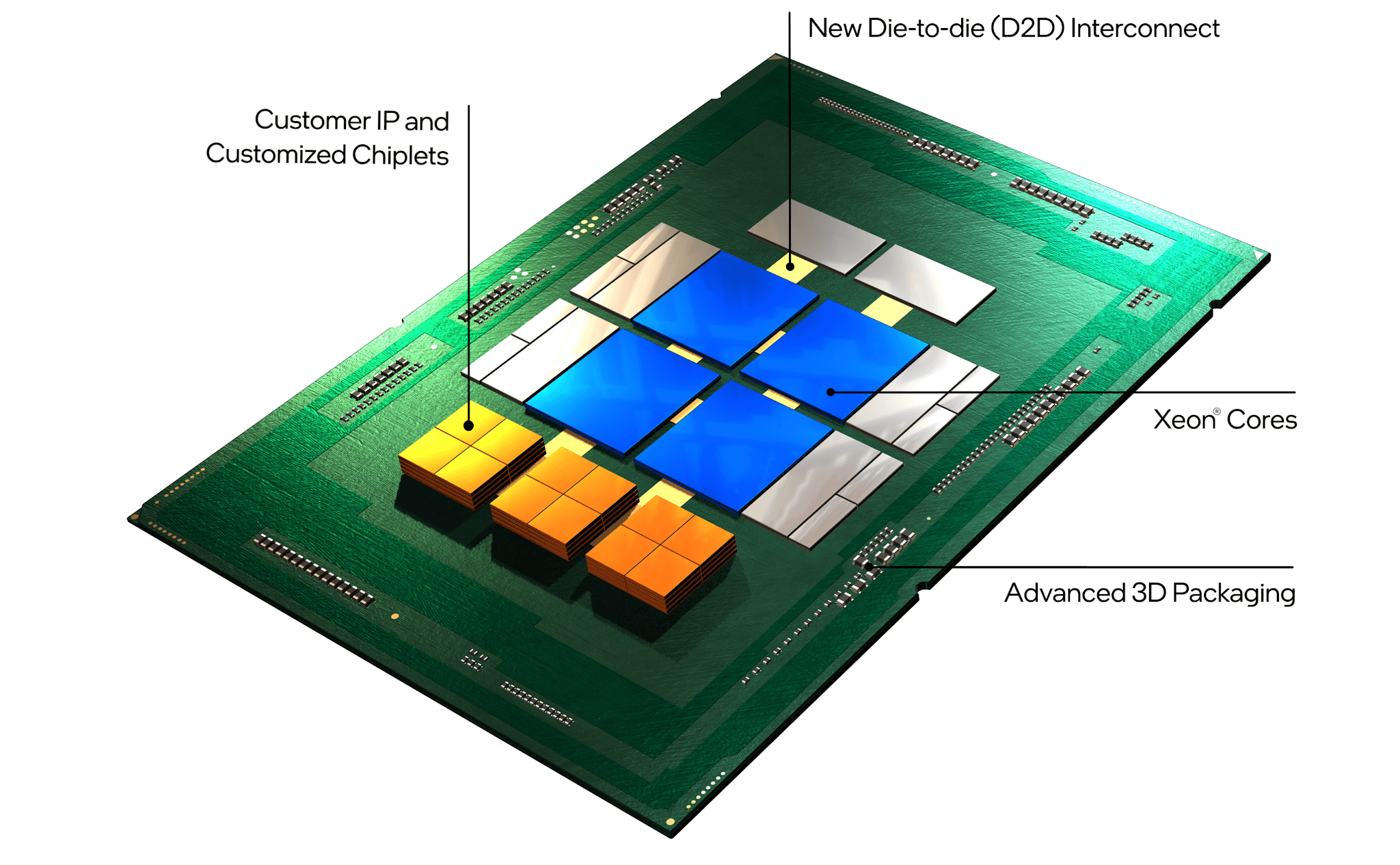
Intel is adopting an internal foundry model for external customers and for its own Intel product lines. The effort will ...

Hyperoptic, the UK’s largest exclusively full fiber internet service provider, will deploy Nokia’s 800GE-capable 7750 SR-s routers, which are powered ...
A private dossier for networking and telecoms










